Players usually get to sign a new contract for one of two reasons:
1. Sustained increase in performance
2. Transferred to a new club
Both of these are two sides of the same coin where some kind of increased performance is rewarded either at the current club or by moving to a different club.
It’s an easy narrative to sell that a player whose contract is running down will put up good performances and try harder to secure that next payday. Whilst after they sign that contract they will try less hard as they have a secure future, and performances will drop.
Whilst that may be true in some specific cases, the integrity of the large majority of players surely wouldn’t be swayed that easily.
That’s what I’ve taken a look at here: how player performance in games leading up to their contract compared to their performance after signing the contract.
They are the top 100 contracts from the English Premier League.
Whilst the player performance measures were taken from match logs on: https://fbref.com/
Player performance is not completely described in counting stats, no matter how advanced. Context is always necessary when interpreting statistics for football performances. This analysis will take a very high level view and take a rolling average of position specific measures in matches leading up to a contract date and then the same after to compare.
Even at this high level there is context to consider. Some of the contracts are due to increased performance levels whilst others are due to transfers which would likely be the result of increased performance.
For transfers, they can only occur in the transfer windows which are either January or in Summer. So some of these will be comparing between seasons and some will be comparing within seasons, but both will be playing with different players and potentially in different roles with their new teams.
For contract extensions in the same teams, they can occur at any time and so could occur mid-season.
Performance measures for positions are as you’d expect:
For forwards they are mainly goalscoring measures
Attacking midfielders are more creative measures
Defensive midfielders are some possession and defensive measures
Central defenders are similar to defensive midfielders actually
Full backs are defensive measures and creativity.
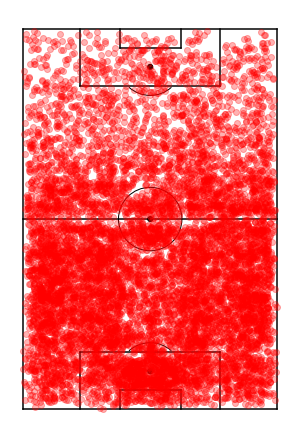
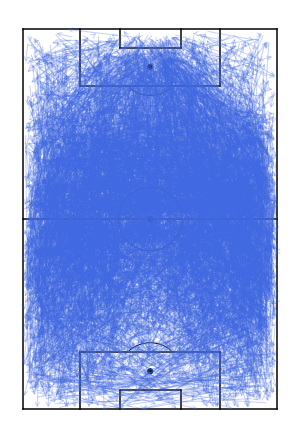
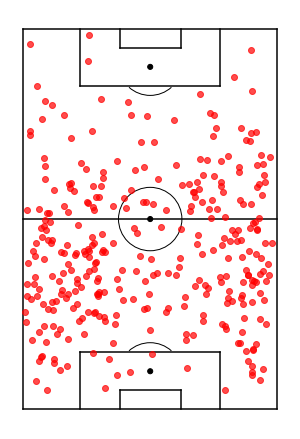
So let’s take a look at some specific players. Below are a selection of high level players including Aubameyang, Kane, Grealish, De Bruyne, Chillwell, Wan Bisakka, Maguire. A mixture of transfers and extensions.
The first up is Aubameyang, who was the inspiration for this work. After signing a large extension with Arsenal it doesn’t feel like he’s hit the same levels as before, and the numbers suggest similar. Potentially guilty of the narrative not trying after securing the extension but more likely just a decline in performance due to age.
Next is Grealish, who has been amazing for Aston Villa, and potential transfer rumours to Man Utd. Though seems like his extension at Villa hasn’t had the same effect as Aubameyang. Arguably Grealish is even better now than before the contract. Potentially due to his age and motivation with the Euros coming up, the contract extension seems deserved.
Lastly is a transfer example with Ben Chilwell, had a great season with Leicester last year and now playing for a ‘better’ team at Chelsea. Though this whole process seems to have completely skipped Chillwell’s mind as his performances are as varied both before and after the transfer and new contract.
Now taking a look at whether contracts seem to affect some positions more than others. Each individual player’s average measure has been averaged to try to find an overall trend.
There are no clear drop offs after signing a new contract. Most of the time immediately before the contract seems to be the worst performances and they seem to pick it up afterwards. Perhaps contract talks have a negative effect on player performances from a mental perspective.
Arguably forwards have the sharpest drop in performance leading up to contracts, and whilst their performance does increase. It’s not certain they’ll return to pre-contract levels.
Forwards’ performance measures are largely affected by goalscoring, which is pretty lucky in itself. The players getting new contract and transfers are those that are likely to be performing well leading up to their contract or transfer. This likely includes some hot goalscoring streaks and over-performing which will be hard to replicate going forwards.
And finally taking a look at all positions together, to try to get an overall view at player performances before and after signing contracts.
It seems that there’s a drop in performance leading up to the contract and then it picks back up afterwards.
This is largely driven by the high pre-contract performances of forwards as discussed earlier. With the remaining positions not as large a difference.
As mentioned multiple times, this sample of players is implicitly biased towards players who have performed well before signing contracts, especially large ones. If looking at all contracts across all leagues and taking into account the contract monetary amount there may be further patterns to find.
But in this sample we seem to be seeing a slight drop in performance leading up to contracts and then a return to mostly similar levels afterwards. There is the inevitable regression to the mean argument which is applicable across all positions. It’s largely affecting positions and players that rely on more variable performance measures like goalscoring rather than midfielders or defenders whose measures include higher volume measures such as touches or passes.
Arsenal’s Invincibles season is unique to the Premier League, they are the only team that has gone a complete 38 game season without losing. They’re considered to be one of the best teams ever to play in the Premier League. Going a whole season without losing suggests they were at least decent at defending, to reduce or completely remove bad luck from ruining their perfect record. This project aims to look into how Arsenal’s defence managed this.
Using StatsBomb’s public event data for the Arsenal 03/04 season* (33 games), I take a look at where Arsenal’s defensive actions take place and how opponents attempted to progress the ball and create chances against them.
The goal is to identify areas of Arsenal’s defensive strengths and the frequent approaches used by opponents. Tasks involved are as follows:
Download and preprocess StatsBomb’s event data
Explore and visualise Arsenal’s defensive actions
Explore and visualise Opponent’s ball progression by thirds
Cluster and evaluate Opponent’s ball progressions
Cluster and evaluate Opponent’s shot creations
A major problem when using many clustering algorithms is identifying how many clusters exist in the data since they require that as an input parameter. Sometimes expert judgement can provide a good estimate. However, some clustering algorithms such as agglomerative clustering require other inputs such as distance thresholds to determine clusters.
When using k-means clustering, to determine the number of clusters the following metrics are used. When using agglomerative clustering, to determine the distance threshold the same metrics are used. They try to consider the density of points within clusters and between clusters.
Sum of squares within cluster:
Calculated using the inertia_ attribute of the k-means class, to compute the sum of squared distances of samples to their closest cluster center.
Known as the Variance Ratio Criterion, defined as the ratio between within-cluster dispersion and between-cluster dispersion. Higher scores signal clusters are dense and well separated.
Average similarity measure of each cluster with its most similar cluster, where similarity is the ratio of within-cluster distances to between-cluster distances. Minimum score is 0, lower values for better clusters.
StatsBomb collect event data for lots of football matches and have made freely available a selection of matches (including all FAWSL) to allow amateur projects to be able to take place. All they ask is to sign up to their StatsBomb Public Data User Agreement here: https://statsbomb.com/academy/. And get access to the data via their GitHub here: https://github.com/statsbomb/open-data
Their data is stored in json files, with the event data for each match identifiable by their match ids. To get the relevant match ids, you can find those in the matches.json file. To get the relevant season and competitions, you can find that in the competitions.json file.
In [2]:
# Load competitions to find correct season and league codeswithopen('open-data-master/data/competitions.json')asf:competitions=json.load(f)competitions_df=pd.DataFrame(competitions)competitions_df[competitions_df['competition_name']=='Premier League']# Arsenal Invincibles Seasonwithopen('open-data-master/data/matches/2/44.json',encoding='utf-8')asf:matches=json.load(f)# Find match idsmatches_df=json_normalize(matches,sep="_")match_id_list=matches_df['match_id']# Load events for match idsarsenal_events=pd.DataFrame()formatch_idinmatch_id_list:withopen('open-data-master/data/events/'+str(match_id)+'.json',encoding='utf-8')asf:events=json.load(f)events_df=json_normalize(events,sep="_")events_df['match_id']=match_idevents_df=events_df.merge(matches_df[['match_id','away_team_away_team_name','away_score','home_team_home_team_name','home_score']],on='match_id',how='left')arsenal_events=arsenal_events.append(events_df)print('Number of matches: '+str(len(match_id_list)))
The coordinates are mapped to a horizontal pitch with the origin (0, 0) in the top left corner, and (120, 80) in the bottom right. Since I am interested in defensive analysis from the point of view of Arsenal, I thought it would be easier to interpret if we converted these to a vertical pitch with Arsenal defending from the bottom and the opposition attacking downwards.
The location tuples for start and pass_end, carry_end are separated. They are all rotated to fit vertical pitch and then I create a universal end location for all progression events.
In [3]:
# Separate locations into x, yarsenal_events[['location_x','location_y']]=arsenal_events['location'].apply(pd.Series)arsenal_events[['pass_end_location_x','pass_end_location_y']]=arsenal_events['pass_end_location'].apply(pd.Series)arsenal_events[['carry_end_location_x','carry_end_location_y']]=arsenal_events['carry_end_location'].apply(pd.Series)# Create vertical locationsarsenal_events['vertical_location_x']=80-arsenal_events['location_y']arsenal_events['vertical_location_y']=arsenal_events['location_x']arsenal_events['vertical_pass_end_location_x']=80-arsenal_events['pass_end_location_y']arsenal_events['vertical_pass_end_location_y']=arsenal_events['pass_end_location_x']arsenal_events['vertical_carry_end_location_x']=80-arsenal_events['carry_end_location_y']arsenal_events['vertical_carry_end_location_y']=arsenal_events['carry_end_location_x']# Create universal end locations for event typearsenal_events['end_location_x']=np.where(arsenal_events['type_name']=='Pass',arsenal_events['pass_end_location_x'],np.where(arsenal_events['type_name']=='Carry',arsenal_events['carry_end_location_x'],np.nan))arsenal_events['end_location_y']=np.where(arsenal_events['type_name']=='Pass',arsenal_events['pass_end_location_y'],np.where(arsenal_events['type_name']=='Carry',arsenal_events['carry_end_location_y'],np.nan))arsenal_events['vertical_end_location_x']=np.where(arsenal_events['type_name']=='Pass',arsenal_events['vertical_pass_end_location_x'],np.where(arsenal_events['type_name']=='Carry',arsenal_events['vertical_carry_end_location_x'],np.nan))arsenal_events['vertical_end_location_y']=np.where(arsenal_events['type_name']=='Pass',arsenal_events['vertical_pass_end_location_y'],np.where(arsenal_events['type_name']=='Carry',arsenal_events['vertical_carry_end_location_y'],np.nan))
As we are only interested in defensive events, we need to define the list of those. The full list of available events is located in the events documentation above.
I have defined all defensive events to use throughout below and filtered all events for those. Due to the nature of event data, these are all on-ball defensive actions. Often defensive plays are off-ball and explicitly deny future events from taking place, so these events may only highlight the end point of a potential sequence of ‘invisible’ defensive plays.
Since event data cannot tell the full defensive story, taking a look at the opposition’s offensive plays may help.
Firstly I remove all set pieces in favour of keeping only open play progressions. This is because defending from open play and set pieces requires different approaches, I will be focusing on open play progressions here.
Need to define what event types we class as ball progressions too. Here I have defined passes, carries and dribbles. The difference between a Carry and a Dribble is that a Dribble is ‘an attempt by a player to beat an opponent’, whilst a Carry is defined as ‘a player controls the ball at their feet while moving or standing still.’ In the data this distinction is clearer since a Carry has a start and end point, whilst a Dribble starts and ends in the same place.
The defined list of ball progression columns were aspirational and things I think would be useful to consider for next time, but didn’t get to look further into.
As mentioned above, when using the vertical pitch it would be useful to have the opponents moving in the opposite direction to the defending team (Arsenal) to feel more interpretable when visualising.
I have separated the ball progressions into thirds on the pitch since different approaches may be taken in different areas of the pitch. More caution would be expected closer to your own goal than in the opponents third.
Narrowing down more towards goal threatening progressions I’ve separated out passes and carries into the penalty area and shot assists.
Finally, dribbles are considered separately since they don’t have a separate end location. There is more focus on the progressions via passes and carries since they have quantifiable start to end progressions up the pitch.
In [5]:
# Remove Set Piecesopen_play_patterns=['Regular Play','From Counter','From Keeper']arsenal_open_play=arsenal_events[arsenal_events['play_pattern_name'].isin(open_play_patterns)]# Define Opponents Ball Progressionevent_types=['Pass','Carry','Dribble']ball_progression_cols=['id','player_name','period','possession','duration','type_name','possession_team_name','team_name','play_pattern_name','vertical_location_x','vertical_location_y','vertical_end_location_x','vertical_end_location_y','pass_length','pass_angle','pass_height_name','pass_body_part_name','pass_type_name','pass_outcome_name','ball_receipt_outcome_name','pass_switch','pass_technique_name','pass_cross','pass_through_ball','pass_shot_assist','shot_statsbomb_xg','pass_goal_assist','pass_cut_back','under_pressure']# Filter Opponents and Ball Progression Columnsopponent_ball_progressions=arsenal_open_play[(arsenal_open_play['team_name']!='Arsenal')&(arsenal_open_play['type_name'].isin(event_types))]opponent_ball_progressions=opponent_ball_progressions[ball_progression_cols]# Reverse locations for opponentsopponent_ball_progressions['vertical_location_x']=80-opponent_ball_progressions['vertical_location_x']opponent_ball_progressions['vertical_location_y']=120-opponent_ball_progressions['vertical_location_y']opponent_ball_progressions['vertical_end_location_x']=80-opponent_ball_progressions['vertical_end_location_x']opponent_ball_progressions['vertical_end_location_y']=120-opponent_ball_progressions['vertical_end_location_y']# Separate events into thirds, penalty areafrom_own_third_opp,from_mid_third_opp,from_final_third_opp,into_pen_area_opp= \
ball_progression_events_into_thirds(opponent_ball_progressions)# Filter shot assistsopponent_shot_assists=opponent_ball_progressions[opponent_ball_progressions['pass_shot_assist']==True]# Filter dribblesopponent_dribbles=opponent_ball_progressions[opponent_ball_progressions['type_name']=='Dribble']
Data Exploration
This is an incredible sparse dataset, there are lots of events and lots of categorical columns to provide much needed context. Most columns aren’t applicable to most events so there are lots of missing or uninteresting values.
There are lots more progressions via Passes than Carries in the opposition’s own third and middle third. This is likely due to the reduced risk of a forward pass compared to a carry. If you lose the ball due to a misplaced pass, the ball is likely higher up the field and the passer is closer to their own goal as an extra defender. If you lose the ball due to being tackled, then you likely lose the ball from where you are and are chasing back to catch up.
In the final third, there is a much more even split between Carries and Passes. Perhaps due to forward passing becoming much harder the further up the pitch and the reduced risk of Carries since you are so far away from your own goal.
(<Figure size 360x720 with 1 Axes>,
<matplotlib.axes._subplots.AxesSubplot at 0x27daea3a1d0>)
Due to the lower volume, we can actually see that there are more dribbles out wide than centrally.
In [16]:
plot_sb_event_location(opponent_dribbles)
Out[16]:
(<Figure size 360x720 with 1 Axes>,
<matplotlib.axes._subplots.AxesSubplot at 0x27db36c0be0>)
Methodology
Event data records all on-ball actions from a match, this is more granular than high level team and player totals. As well as the event types, the event locations and extra information for the respective event type are recorded to provide context where possible. For offensive events such as passing and shooting, event data is great since they are usually on-ball actions. There are on-ball defensive actions such as tackles, interceptions and recoveries which are well captured by event data, these are the defensive events that I will be using. Using these defensive events, we can see where these events frequently occur on the pitch for Arsenal compared to their opposition. The key nuance is that just because these are the defensive events recorded, doesn’t mean they are all of the defensive plays that take place on the pitch.
The hard part about defensive analysis is that a large proportion of defending are non-events and won’t be captured by event data. If an opportunity to pass the ball to your striker is removed due to a defensive player blocking the passing lane, that pass will not happen and will not be recorded as such. The effective defensive play was to deny a potential event taking place for the offensive team.
Using event data to evaluate defenses can be done by using a combination of the defensive events from Arsenal and the offensive actions from Arsenal’s opponents. Arsenal’s defensive events will show where their on-ball defending took place. Arsenal’s opponents’ offensive events will show how they approached attacking Arsenal, this may be the offensive team getting their way or Arsenal’s defence forcing opponents to play in a certain way. From Arsenal’s success, the majority of the time it’s the latter.
To look at Arsenal’s defensive events, I plot the defensive events in a gridded 2D histogram across the pitch with marginal density plots along each axis to highlight areas of high activity. The same is done for Arsenal’s opponents and the differences can be highlighted using the ratio.
To look at Arsenal’s opponents events, I specifically look at ball progression including passes, carries and dribbles. These are separated into similar locations on the pitch since different approaches will be required:
From their own third forwards
From the middle third forwards
From the final third forwards
Into the penalty area
Shot assists
These categories of ball progressions are clustered using K-Means on the start and end locations to group similar ball progressions for each area of the pitch. The assumed number of clusters is decided using expert judgement and four evaluation measures:
Sum of squared variance within cluster
Silhouette Coefficient
Calinski-Harabasz Index
Davies-Bouldin Index
These clusters will represent the approaches that opponents tried to attack and create chances against Arsenal. No concrete results will be able to be drawn from only this, but they will give a better understanding.
Defensive Events
In [17]:
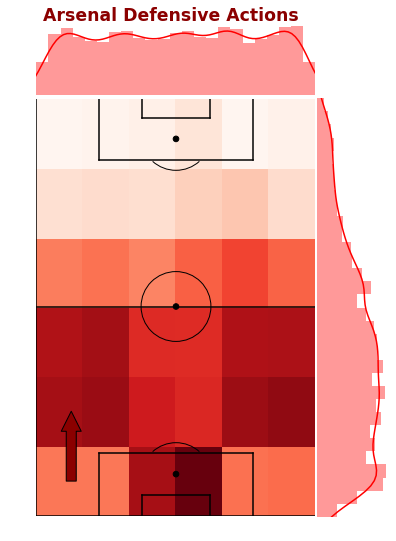
# Arsenal Defensive Events Density Gridfig,ax,ax_histx,ax_histy=plot_sb_event_grid_density_pitch(arsenal_defensive_actions)# Titlefig.suptitle("Arsenal Defensive Actions",x=0.5,y=0.92,fontsize='xx-large',fontweight='bold',color='darkred')# Direction of play arrowax.annotate("",xy=(10,30),xycoords='data',xytext=(10,10),textcoords='data',arrowprops=dict(width=10,headwidth=20,headlength=20,edgecolor='black',facecolor='darkred',connectionstyle="arc3"))
Out[17]:
Text(10, 10, '')
Rather than the overplotting mess we saw above, the above plot is a combination of a 2D histogram grid and marginal density plots across each axis. We can see that the frequency of defensive actions is evenly spread left to right and more heavily skewed to their own half.
More specifically, the highest action areas are in front of their own goal and out wide in the full back areas above the penalty area. Defensive actions in their own penalty area are expected as that the closest to your goal and crosses into the box are dealt with.
The full back areas seem to be more proactive in making defensive actions before the opponent gets closer to the byline. Passes and cutbacks from these areas close to the byline and penalty are usually generate high quality shooting chances, so minimising the opponents ability to get here is great.
In [18]:
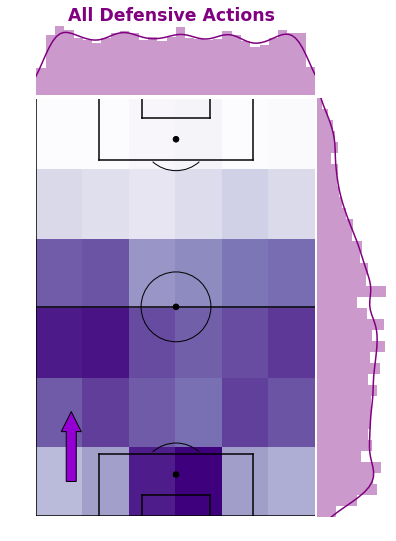
# All Defensive Events Density Gridfig,ax,ax_histx,ax_histy=plot_sb_event_grid_density_pitch(defensive_actions,grid_colour_map='Purples',bar_colour='purple')# Titlefig.suptitle("All Defensive Actions",x=0.5,y=0.92,fontsize='xx-large',fontweight='bold',color='purple')# Direction of play arrowax.annotate("",xy=(10,30),xycoords='data',xytext=(10,10),textcoords='data',arrowprops=dict(width=10,headwidth=20,headlength=20,edgecolor='black',facecolor='darkviolet',connectionstyle="arc3"))
Out[18]:
Text(10, 10, '')
Here we have all defensive events across the matches that Arsenal were in, so Arsenal will be a major contributor to these frequencies. It’s interesting to see the events still largely take place in their own penalty area, but less so in the full back areas.
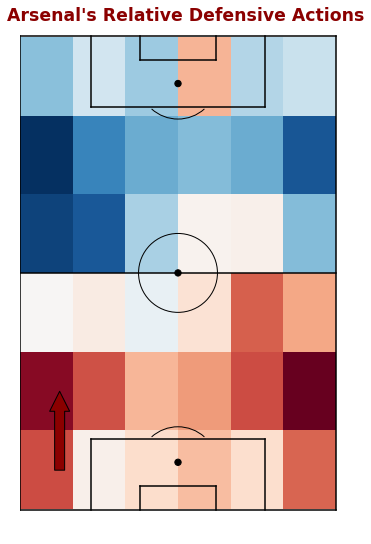
Whilst seeing all defensive events gave some insight into what everyone was doing overall, we can also take a look at the relative difference between Arsenal’s defensive events and the overall view. This density grid shows where Arsenal had more events than overall in red and less than overall in blue.
The darkest red areas are again the full back areas, suggesting that Arsenal’s full backs performed more on-ball defensive actions than their opponents. Whereas they defended their penalty area about as evenly as opponents and less frequently in their opponent’s half.
By taking a look at opponent’s ball progressions we can get potentially see the opponent’s point of view here. Do Arsenal’s full back areas have so many defensive events because they are ‘funneling’ their opponents there as they see it as a strength or do Arsenal’s opponents target and exploit their full back areas?
Ball Progression
Own Third
In [20]:
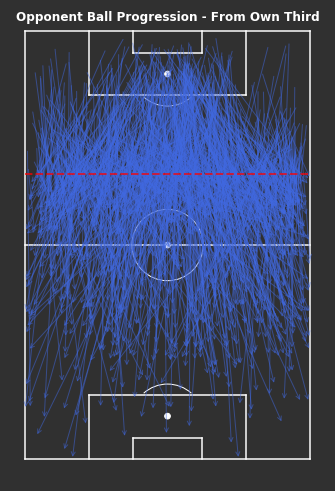
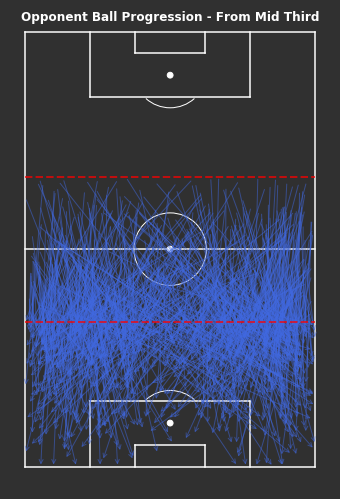
# From Own Third - Ball Progressionsfig,ax=plot_sb_events(from_own_third_opp,alpha=0.5,figsize=(5,10),pitch_theme='dark')# Set figure colour to dark themefig.set_facecolor("#303030")# Titleax.set_title("Opponent Ball Progression - From Own Third",fontdict=dict(fontsize=12,fontweight='bold',color='white'),pad=-10)# Dotted red line for own thirdax.hlines(y=80,xmin=0,xmax=80,color='red',alpha=0.7,linewidth=2,linestyle='--',zorder=5)plt.tight_layout()
Even whilst only looking at the ball progressions from their own third, it’s still hard to identify any trends or patterns of play. There are lots of longer passes, though I have only included progressions of at least 10 yards.
In [21]:
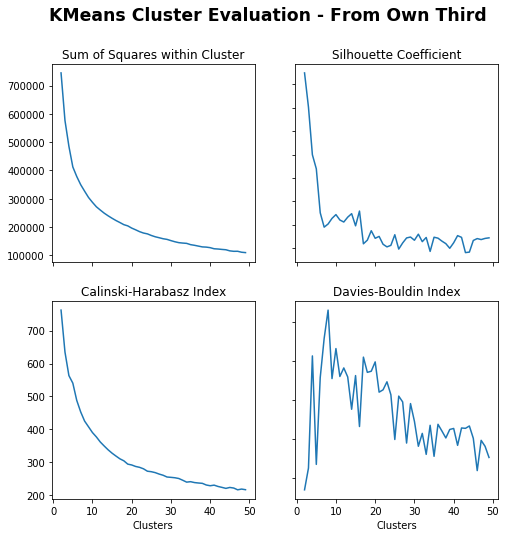
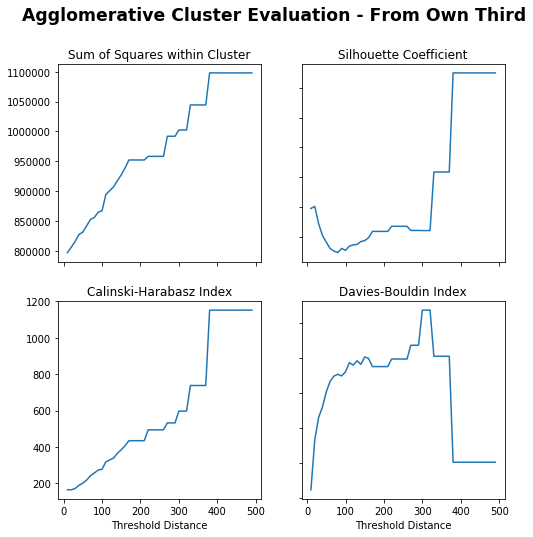
# Create cluster evaluation dataframe for up to 50 clustersown_third_clusters=cluster_evaluation(from_own_third_opp,50)# Plot cluster evaluation metrics by cluster numbertitle="Cluster Evaluation - From Own Third"fig,axs=plot_cluster_evaluation(own_third_clusters)fig.suptitle(title,fontsize='xx-large',fontweight='bold')
Out[21]:
Text(0.5, 0.98, 'Cluster Evaluation - From Own Third')
For K-Means, across each metric it looks as though the ideal number of clusters is roughly 15, I will choose 16 for a 4×4 grid.
In [22]:
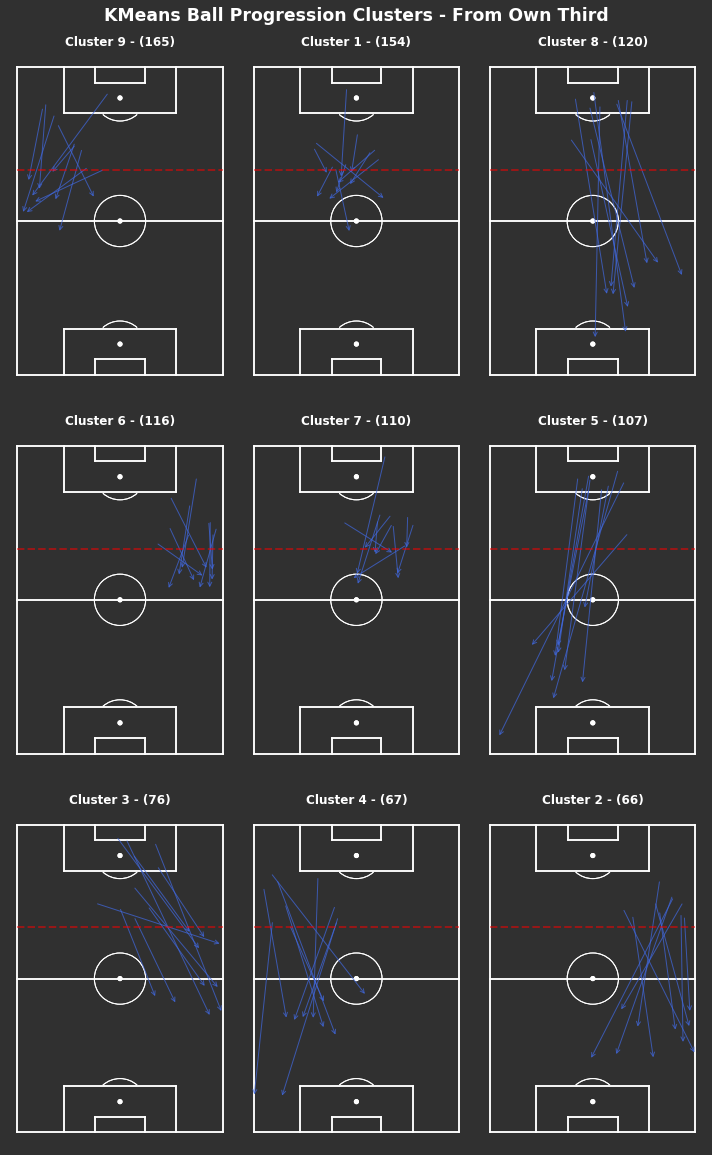
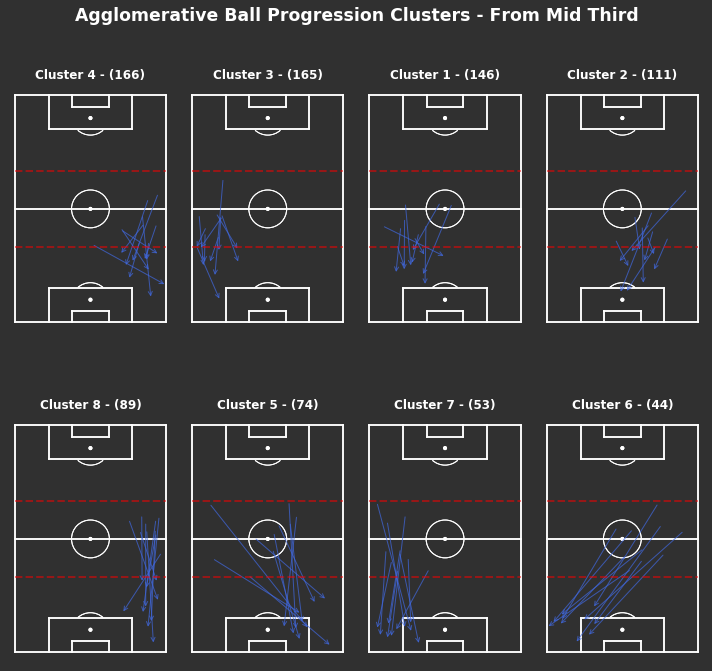
np.random.seed(1000)# KMeans based on chosen number of clusterscluster_labels_own_third=kmeans_cluster(from_own_third_opp,16)# Plot each clustertitle="Ball Progression Clusters - From Own Third"fig,axs=plot_individual_cluster_events(4,4,from_own_third_opp,cluster_labels_own_third)# Titlefig.suptitle(title,fontsize='xx-large',fontweight='bold',color='white',x=0.5,y=1.01)# Dotted red lines for own third across all axesforaxinaxs.flatten():ax.hlines(y=80,xmin=0,xmax=80,color='red',alpha=0.5,linewidth=2,linestyle='--',zorder=5)
We find that the most frequent cluster types for progressing the ball from their own third are shorter progressions into the middle third. There are short progressions centrally in clusters 12 and 7, with wider progressions in clusters 3 and 13.
Shorter progressions are easier to complete and less risky, so not surprising that they are the most frequent. This says nothing for how quality or sustainable these progressions are.
Middle Third
In [23]:
# From Mid Third - Ball Progressionsfig,ax=plot_sb_events(from_mid_third_opp,alpha=0.5,figsize=(5,10),pitch_theme='dark')# Set figure colour to dark themefig.set_facecolor("#303030")# Titleax.set_title("Opponent Ball Progression - From Mid Third",fontdict=dict(fontsize=12,fontweight='bold',color='white'),pad=-10)# Dotted red lines for middle thirdax.hlines(y=[40,80],xmin=0,xmax=80,color='red',alpha=0.7,linewidth=2,linestyle='--',zorder=5)fig.tight_layout()
Ball progressions from the middle third seem to have trajectories that are more dense out wide, so the ball rarely travels through the middle of the pitch in Arsenal’s own third. This may be another indicator that the ball is being directed outside, likely because there are lots of players located centrally.
In [24]:
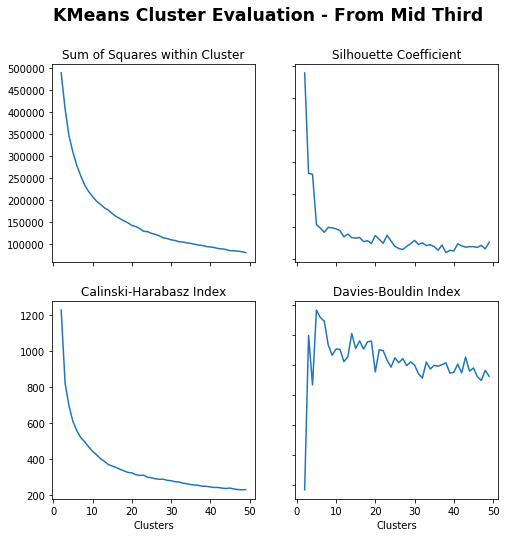
# Create cluster evaluation dataframe for up to 50 clustersmid_third_clusters=cluster_evaluation(from_mid_third_opp,50)# Cluster Evaluations - From Mid Thirdtitle="Cluster Evaluation - From Mid Third"fig,axs=plot_cluster_evaluation(mid_third_clusters)fig.suptitle(title,fontsize='xx-large',fontweight='bold')
Out[24]:
Text(0.5, 0.98, 'Cluster Evaluation - From Mid Third')
For progressions from the middle third, the ideal number of clusters looks to be roughly 10. I choose 9 for a 3×3 grid.
In [25]:
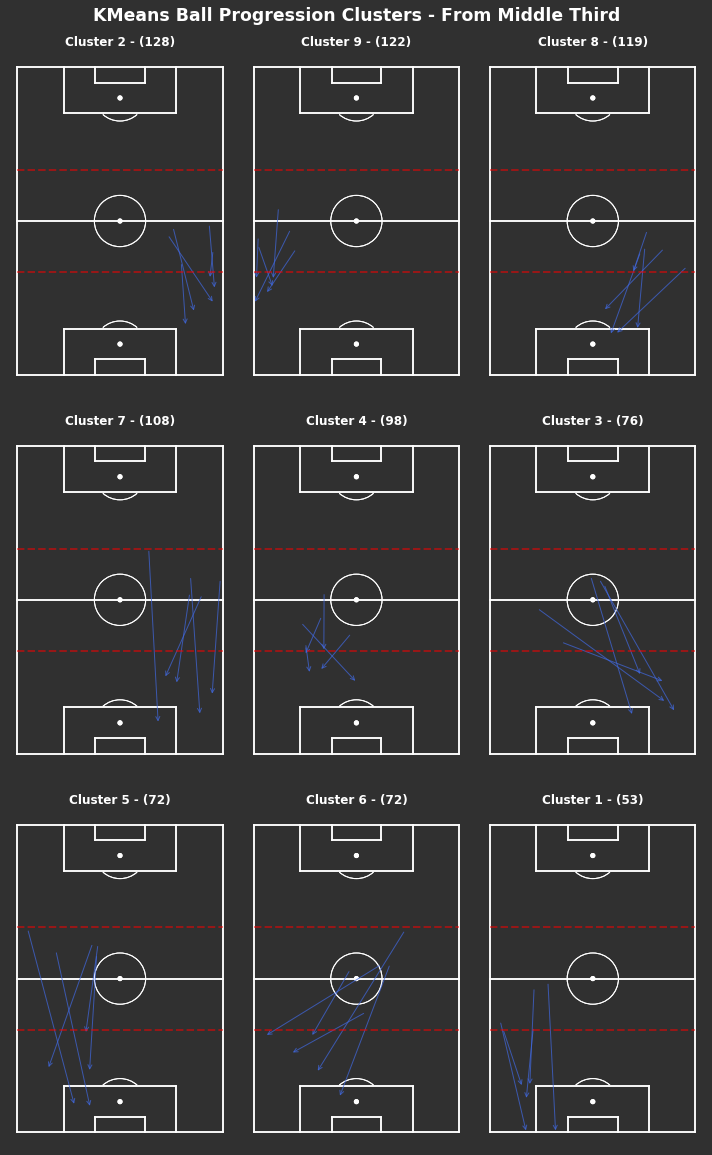
np.random.seed(1000)# KMeans based on chosen number of clusterscluster_labels_mid_third=kmeans_cluster(from_mid_third_opp,9)# Clustered Ball Progressions - From Mid Thirdfig,axs=plot_individual_cluster_events(3,3,from_mid_third_opp,cluster_labels_mid_third)# Titlefig.suptitle("Ball Progression Clusters - From Middle Third",fontsize='xx-large',fontweight='bold',color='white',x=0.5,y=1.01)# Dotted red lines for middle third across all axesforaxinaxs.flatten():ax.hlines(y=[40,80],xmin=0,xmax=80,color='red',alpha=0.5,linewidth=2,linestyle='--',zorder=5)
Similar to the progressions from their own third, the most frequent progressions from the middle third are shorter down the wide areas in clusters 2 and 9, with some longer progressions in clusters 7 and 5. Clusters 8 and 4 suggest a number of progressions do make it into the centre of Arsenal’s own half.
Final Third
In [26]:
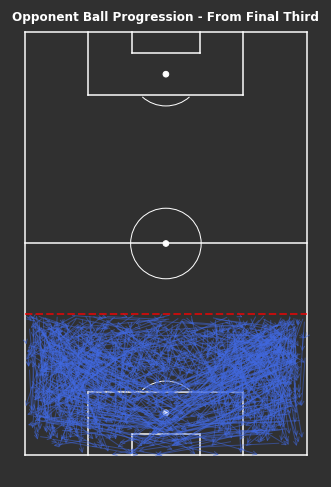
# From Final Third - Ball Progressionsfig,ax=plot_sb_events(from_final_third_opp,alpha=0.5,figsize=(5,10),pitch_theme='dark')# Set figure colour to dark themefig.set_facecolor("#303030")# Titleax.set_title("Opponent Ball Progression - From Final Third",fontdict=dict(fontsize=12,fontweight='bold',color='white'),pad=-10)# Dotted red line for final thirdax.hlines(y=40,xmin=0,xmax=80,color='red',alpha=0.7,linewidth=2,linestyle='--',zorder=5)fig.tight_layout()
Once in the final third, the progressions are less vertically direct. Hard to tell here, but looks like lots of shorter progressions and longer direct progressions into the box, likely crosses.
In [27]:
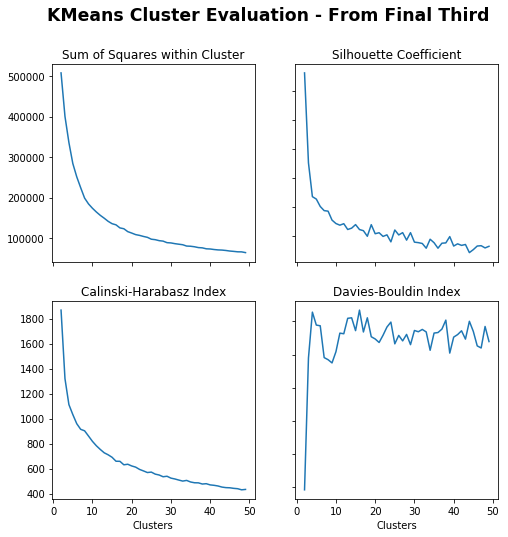
# Create cluster evaluation dataframe for up to 50 clustersfinal_third_clusters=cluster_evaluation(from_final_third_opp,50)# Cluster Evaluations - From Final Thirdfig,axs=plot_cluster_evaluation(final_third_clusters)fig.suptitle("Cluster Evaluation - From Final Third",fontsize='xx-large',fontweight='bold')
Out[27]:
Text(0.5, 0.98, 'Cluster Evaluation - From Final Third')
For progressions from the final third, the ideal number of clusters looks to be roughly 10. I choose 9 for a 3×3 grid.
In [28]:
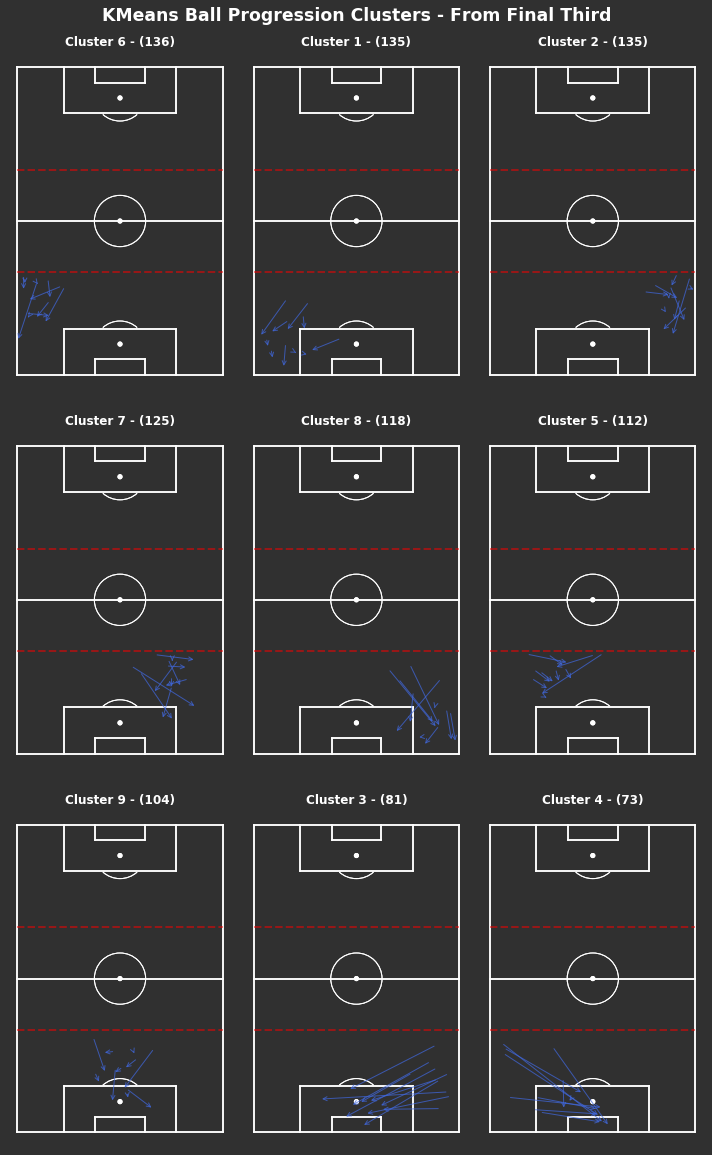
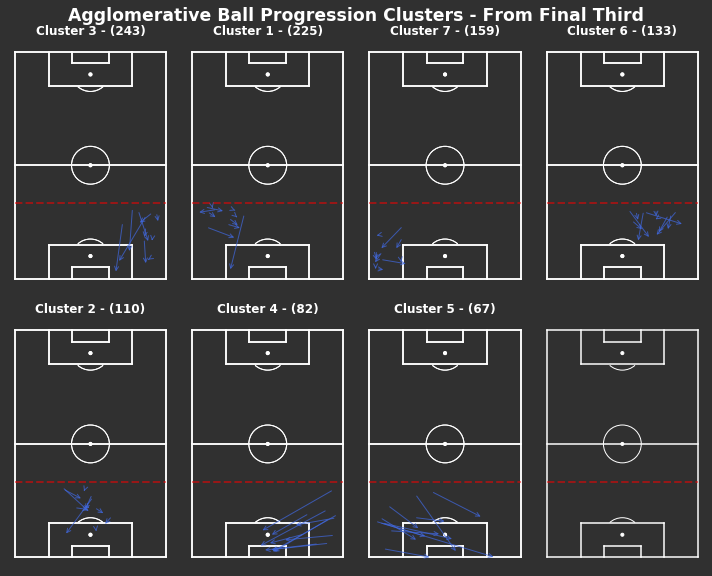
np.random.seed(1000)# KMeans based on chosen number of clusterscluster_labels_final_third=kmeans_cluster(from_final_third_opp,9)# Plot clusters individuallyfig,axs=plot_individual_cluster_events(3,3,from_final_third_opp,cluster_labels_final_third)fig.suptitle("Ball Progression Clusters - From Final Third",fontsize='xx-large',fontweight='bold',color='white',x=0.5,y=1.01)# Dotted red lines for final third across all axesforaxinaxs.flatten():ax.hlines(y=40,xmin=0,xmax=80,color='red',alpha=0.5,linewidth=2,linestyle='--',zorder=5)
Again, the most frequent progressions appear to be short and out wide all clusters except 3 and 4. Clusters 3 and 4 are the least frequent, but are consistent in entering the penalty area.
Penalty Area
In [29]:
# Into Penalty Area - Ball Progressionsfig,ax=plot_sb_events(into_pen_area_opp,alpha=0.7,figsize=(5,10),pitch_theme='dark')# Set figure colour to dark themefig.set_facecolor("#303030")# Titleax.set_title("Opponent Ball Progression - Into Penalty Area",fontdict=dict(fontsize=12,fontweight='bold',color='white'),pad=-10)fig.tight_layout()
The majority of progressions into the penalty area come from out wide, however there are some that are incredibly direct and even from their own half.
In [30]:
# Create cluster evaluation dataframe for up to 50 clusterspen_area_clusters=cluster_evaluation(into_pen_area_opp,50)# Cluster Evaluations - Into Pen Areafig,axs=plot_cluster_evaluation(pen_area_clusters)# Titlefig.suptitle("Cluster Evaluation - Into Penalty Area",fontsize='xx-large',fontweight='bold')
Out[30]:
Text(0.5, 0.98, 'Cluster Evaluation - Into Penalty Area')
For progressions into the penalty area, the ideal number of clusters looks to be roughly 10. I choose 9 for a 3×3 grid.
In [31]:
np.random.seed(1000)# KMeans based on chosen number of clusterscluster_labels_pen_area=kmeans_cluster(into_pen_area_opp,9)# Plot individual clustersfig,axs=plot_individual_cluster_events(3,3,into_pen_area_opp,cluster_labels_pen_area,sample_size=5)# Titlefig.suptitle("Ball Progression Clusters - Into Penalty Area",fontsize='xx-large',fontweight='bold',color='white',x=0.5,y=1.01)
Out[31]:
Text(0.5, 1.01, 'Ball Progression Clusters - Into Penalty Area')
For penalty area entries, most are from out wide in the full back areas, and close to the by line in clusters 2 and 6. These are generally areas that provide quality penalty area entries, you want to minimize these as much as possible.
Shot Assists
In [32]:
# Shot Assistfig,ax=plot_sb_events(opponent_shot_assists,pitch_theme='dark')# Set figure colour to dark themefig.set_facecolor("#303030")# Titleax.set_title("Opponent Ball Progression - Shot Assists",fontdict=dict(fontsize=12,fontweight='bold',color='white'),pad=-10)fig.tight_layout()
Shot assists seem to be largely random, the criteria of having a shot attached to the end of the pass is incredible strict and contextual to other players.
In [33]:
# Create cluster evaluation dataframe for up to 50 clustersshot_assist_clusters=cluster_evaluation(opponent_shot_assists,50)# Cluster Evaluations - Shot Assistsfig,axs=plot_cluster_evaluation(shot_assist_clusters)fig.suptitle("Cluster Evaluation - Shot Assists",fontsize='xx-large',fontweight='bold')
When looking at only shot assists, there are lots from the left full back area as well as passes through the middle. Both of these are areas where if you can complete a pass towards goal then there is a higher chance of generating a shot. However, shot assists that do not penetrate the penalty area suggest that those shots are likely from further out and of lower quality.
Again, there is no indication as to the quality of these shots produced and there is no context to compare to the wider league. But what is promising is that there is nothing significant standing out and and the common breaches of the Arsenal defence are just good progressions if they do come off. It’s not clear here how many more of these types of opportunities that were prevented due to defensive plays off the ball.
Overview
Opponent’s Ball Progressions
Across ball progressions throughout the whole pitch, the most frequent were shorter and in the wide areas. This is expected as shorter progressions are lower risk and wide areas are less important to defend, so are areas the defending team are willing to concede.
The length of progressions from the middle third appear to be longer than in their own third or in the final third. Context is needed in all individual circumstances but this may be due to a lower risk of failure due to being further away from your own goal or trying to take advantage of a short window of opportunity to quickly progress the ball longer distances into the final third.
When in the final third, the progressions shorten again. This is not due to lower risk, but likely due to a more densely populated area. There will be the majority of all players on the pitch within a single half of the pitch, navigating through there requires precision and patience from the offensive team.
Any completed progression into the penalty area is a success for the offensive team. There is a high chance you will create a shot and if you do it’s likely to be a higher quality shot than from outside the penalty area. Though not all completed progressions into the penalty area are created equal. If it’s a completed carry into the penalty area then awesome, you likely have the ball under control and can get a pretty good shot or extra pass. If it’s a completed pass then it depends how the player receives it, aerially or on the ground makes a difference to the shot quality. Aerial passes are harder to control and headers are of less quality than shots with the feet, however aerial passes are usually easier to complete into the penalty area. So higher quantity, lower quantity than ground passes or carries.
Shot assists rely on there being a shot at the end of them. So circularly they created a shot so are ‘good’ progressions but also they are ‘good’ progressions because they created a shot. As we can see, they are much more random which means it’s harder to understand without context why they created shooting opportunities since the locations alone don’t tell us anything. Although the context is available within StatsBomb’s data, I haven’t taken a further look here.
Arsenal’s Defensive Events
When considering how these progressions affect Arsenal’s defensive events, remember that the majority of their defensive events were performed out wide in the full back areas and in their own penalty area. Particularly out wide in the full back areas more than other teams, whilst defensive events within their own penalty area around the same as other teams.
At each third of the pitch, the most frequent ball progressions were out wide, which places the ball frequently in the full back areas. Due to the nature of defensive events, the only events recorded would be the on-ball actions that were defined including pressures, ball recoveries, tackles etc. The ball needs to be close to you to be able to perform these actions and get them recorded as events, so the opponent ball progression frequently going out wide combined with Arsenal’s defensive events in their defensive wide positions fits together well.
What this doesn’t tell us is if these are causally linked or just correlate. I would suggest there are more ball progressions made out wide than centrally in all of football due to the defence more likely willing to concede that space, so this doesn’t necessarily tell us much about Arsenal specifically. Though in Arsenal’s matches, they do perform defensive events in their full back areas more than other teams, which may suggest that there is something more than just correlations.
If it is a specified game plan to funnel the ball out wide and perform defensive events there, then Arsenal have done a great job at completing that. It’s a robust defensive plan if you can get it to work, the wider the ball is, the harder it is to score immediately from there. When defending it’s often useful to utilise the ends of the pitch as an ‘extra’ defender, which makes it easier to overwhelm offensive players.
Conclusion
I set out to try to understand why Arsenal’s defense worked so well during their unbeaten season. Using StatsBomb’s event data for the majority of the season, I analysed where Arsenal’s defensive events were performed and how that compared to their opponents. This could only tell part of the story since defensive events only cover on-ball actions. It is accepted that defensive actions cover a whole lot more than just on-ball actions so further analysis was needed. I analysed how their opponents progressed the ball up the pitch form each third and how they created shots by clustering the locations to identify most frequent types of progressions. Considering both sides, it’s clear that much of Arsenal’s defensive work happens in their full back areas and their opponents try to progress the ball down the flanks. What is not clear is if Arsenal are causing this to happen via off the ball actions or if it’s just coincidence.
I found it hard to directly answer the question that I set out to, that’s likely due to a poor question in being too broad. However, I definitely am further along the road than when I started and has been interesting trying to work through these problems.
It was great working with event level data and trying to find interesting ways to communicate visualisations, hopefully the plots combined with the football pitches work well to add to understanding.
Next time I would definitely be more narrow and specific with the question I set out to answer.
A potential improvement for next time would be to try alternative clustering approaches to avoid the need to identify the optimal number of clusters. Using hierarchical clustering with a distance based threshold could work to group clusters based on their spatial similarities and differences more naturally. You would still need to choose the optimal distance threshold but that seems more intuitive than choosing number of clusters.
Another useful tool would be to get access to tracking level data for these matches. For defensive analysis there is much more emphasis on off-ball events and distances between all the players on the pitch, tracking data would provide the locations of all players on the pitch and the ball at all times. This would provide much greater detail but also be much more complicated to work with.
WordPress conversion from # 26 – Arsenal’s Invincibles Defence.ipynb by nb2wp v0.3.1
As the new 2020/21 Premier League season is about to get underway, a big question is whether Liverpool can replicate their utter dominance. They’ve won the league by an unprecedented margin, and it never really looked like anything else was going to happen. Not even Pep Guardiola’s Manchester City teams that have just achieved 100 and 98 points in the previous two years could come close, they hadn’t been able to maintain that pace for a third season. Liverpool have just had consecutive 97 and 95 point seasons, hoping to replicate that form for the upcoming third season.
It had been noted that despite winning the league in record time, Liverpool’s expected goals and goal difference was still not as good as Manchester City’s. This suggests the idea that Manchester City were in fact the better team over the course of the season and that Liverpool have been merely lucky to win the league by such a margin.
Using shot distance, shot times and expected goals from www.fbref.com, I’ve approximate expected goals per shot for both Liverpool and Manchester City’s 2019/20 Premier League season. The total expected goal totals across each match have been proportioned out using shot distance to approximate expected goals per shot. Per shot information allows expected goals and minutes aggregation by gamestate.
Gamestate is an important factor in contextualising football matches. Stronger teams usually spend more time winning a game than weaker teams. Teams that are winning are no longer under obligation to push forward as much, with the losing team responsible for trying to get back into the game.
Across both the 97 and 95 point Liverpool seasons in 2018/19 and 2019/20, Liverpool achieved the majority of their expected goals in winning gamestates. Notably in the recent 2019/20 season, they actually achieved more expected goals winning by a single goal than drawing.
Whereas for Manchester City, there is a clear distinction between their 98 point 2018/19 season and the recent 2019/20 season. They have earned a much larger proportion of their expected goals at a neutral gamestate than their title winning season, they are clearly creating the chances but perhaps have been wasteful. It’s also noticeable that they create lots of their expected goals when they’re already 3+ ahead and lots more when losing than the previous year.
Now lets take a look at how long each team has spent in each gamestate across the season.
Much like the expected goals charts, the proportion of minutes played between each club suggests a clear difference in approach that each team needed to adopt. Liverpool have spent a much larger proportion of their time winning by 1 goal, whilst Manchester City spent more time Losing and winning by 3+.
They both spent a similar proportion of time at neutral gamestates, though Manchester City’s expected goals at this gamestate were much higher. This suggests more chances and shots were required to go ahead in the game, Liverpool went ahead more efficiently and spent more time ahead at +1.
As mentioned earlier, your approach can change once you are winning. You no longer need to force anything or take risks, the responsibility to equalise or reduce the deficit is on the opponents so they need to take risks. Playing with no risks allows for a higher floor in performance, no doubt being in winning positions so much helped Liverpool maintain their momentum throughout the season. When you aren’t winning, you are required to create chances and shoot more which in turn helps build up your expected goals numbers.
Manchester City built up a lot of expected goals whilst at a neutral gamestate, when they were losing and when they were 3+ ahead. At neutral gamestates, these are the goals that convert into points most easily, and Liverpool were more efficient than Manchester City. When losing, you need to create shots (rack up expected goals numbers) to get back in the games, but you’re only losing because you didn’t score the first goal. When you’re 3+ ahead, these shots and expected goals likely won’t change the points returns of the match. Manchester City spent lots of time either needing to score goals in losing or neutral gamestates or absolutely crushing teams, and little in between, which perhaps explains their ridiculous expected goals numbers.
Liverpool spend little time and expected goals to get from neutral to +1 gamestates, meaning they could spend reduced time with responsibility to take more risks. They spent little time losing and lots of time ahead +1, with little time spent at 3+. They get ahead early and then not much else happened in the game, pretty good strategy to win. They’re deserving champions and perhaps explains why their expected goals aren’t as bonkers as Manchester City’s.
It’s finally nearing end of this current season, so I wanted to have a look at past league points totals to get some context for how this season is shaping up.
To do so, I’ve taken data from www.fbref.com for league tables for last 24 years of 38 game seasons in the Premier League. A jupyter notebook used to get the league tables and create the plots is in my GitHub here: https://github.com/ciaran-grant/premier_league_points
This post looks to investigate the following three questions:
How do points totals recently compare to early Premier League seasons?
What has happened to the gap between the champions and relegation survivors?
How many points do you tend to need to qualify for Europe recently?
History of Premier League Points
Looks like the top 6 have been getting more points recently at the expense of the bottom half. There are only a set number of points available across all teams, the more points the big boys get the less available for the lower teams.
Does this mean there is an increasing gap between the top teams and the rest? We’ve gone through several incarnations with a top 4, then top 6 and now arguably a top 2 with Liverpool and Manchester City.
Champions and Relegation Survival
Relegation survival has been calculated as one more point than the points achieved by 18th place for simplicity of not getting too picky about goal difference.
Only 4 times out of the 24 seasons has a team required 40 points to survive, whilst it seems around 35 will usually be enough to be safe. Of course you want to aim for more points, but this seems to bust the myth of 40 points required for survival, often less is sufficient.
The points required to become champions has increased, meaning the gap between champions and relegation survival has increased in recent years. 2016/17, 17/18, 18/19 have been 3 of the highest points totals ever, only Chelsea in 04/05 with 95 in between here.
Could just be recency bias, but Liverpool were on track for 100+ this year. They’re likely to actually get 95+ and it’s expected both Liverpool/City to get close to 90+ again next year. They’re making 90 points seem normal and is becoming the minimum to win now.
How about qualifying for Europe?
European Qualification
It’s not only the Champions that has seen a point inflation, and in line with the whole top 6 sweeping up more points looks like there’s more points required to qualify for both European competitions as well.
The last decade has seen a higher average points requirement for getting both Champions League and Europa League qualifications, with 70 points for Champions League and 60 points for Europa League.
Current Season Context
Champions Liverpool are on 93 points with 2 games left, and likely they will break 95. This will make the last 3 seasons the highest 3 totals ever by a Premier League Champion. They could still win the league this year with less points than last year (97) and be in the top 4 highest points scoring teams ever.
Champions League qualification looks like coming up short of the 70 points mark. Chelsea, Leicester and Manchester United all comfortably in Europe sitting above 60 points but all to play for with 2 games left. Will be a low bar for both European competitions this year.
As for relegation survival, Bournemouth and Aston Villa both sit on 31 points with 2 games left. If things stay as they are, 32 points required for survival is the lowest since 09/10 where 31 points were needed. That year 40 points would’ve been good enough to finish 14th, this year 40 points looks good for 15th.
Final Thoughts
This season seems to be getting stretched by how ridiculously good Liverpool have been for 90% of the season, subconsciously or otherwise taking their foot off the gas once the title was wrapped up. Apart from prime Messi/Ronaldo Barcelona and Real Madrid teams, I wouldn’t expect many teams even get above 90 points, let alone dream of nearing 100.
Are these points totals also consistent across other 38 game seasons in France, Italy and Spain? How does this change when you consider Germany’s 34 game season or the 46 game seasons in the Football League?
Here’s a quick look back to see where the suspended seasons were left. I’m going to take a look at how efficient teams have been at converting shots into shots on target whilst simultaneously limiting shots on target against. How many shots a team takes is the most basic indicator of attacking output. You don’t shoot, you don’t score after all. Shots on target goes a step further to add a qualitative element to the shots. You don’t shoot on target, you don’t score.
If shots are indicative of how likely a team is to score and shots on target are even better, then we can also turn that around defensively. To win a game you need to score more goals than the opponent, which means that as well as trying to score yourself, you need to prevent the opposition from scoring. Reducing the shots conceded likely reduces the chances to concede a goal, and reducing the shots on target conceded does even better.
During a game, teams will try to maximise their own chances of scoring and reduce the opposition’s chances of scoring at the same time. A measure that captures both aspects of this sufficiently is known as the total shots ratio, with a respective total shots on target ratio as well. For a specific game, the total shot ratio is calculated for each respective team below:
Total Shot Ratio = Shots by Team / Total Shots of both Teams
Since every shot one team takes is a shot conceded by the other team, the sum of ratios for each team will always be 1. This also means that a total shots conceded ratio can be calculated, which turns out to be equal to the total shot ratio for the opposition in a single game.
This measure considers the proportion of shots you take against the total shots in a game. This means that if both teams have lots of shots, then the match is more likely to be equal. Whereas if one team takes lots of shots AND stops the opponent from taking lots of shots then that must be better, which is reflected here.
I’ve taken the shot and shots on target information for each match so far in each league to calculate the total shot ratio and total shots on target ratio for each match. Although not every team has played each other just yet, an average of these per game ratios was easiest to represent how each team has performed so far. Teams with high total shots on target ratios are likely to be the stronger teams in the league. Teams with higher total shots on target ratios than total shots ratios appear to be more efficient in terms of creating shots on target for themselves and limiting their opponents to just shots. Whilst teams with lower total shots on target ratios than total shots ratios seem to adhere to quantity over quality when it comes to shot selection or are susceptible to concede lots of shot on target.
Below are the results for each league, they seem to be pretty good approximations for the current league tables and manages to potentially group teams into tiers.
La Liga
La Liga 2019/20 – Total Shots Ratios and Total Shots on Target Ratios
Barcelona and Valencia are both getting a much higher proportion of shots on target in their matches, suggests that they perhaps are hesitant to shoot and rather manufacture better chances. Or they are great at limiting their opponents to settling for off target shots
Sevilla, Eibar and Espanol are at the opposite end of the spectrum, pretty inefficient at both ends
Real Sociedad are deserving of their top 4 place and Bilbao arguably should be better off than their mid table place suggests
Serie A
Serie A 2019/20 – Total Shots Ratios and Total Shots on Target Ratios
Yet another reason why Atalanta are so good this year, they create shots on target at a higher rate than their opponents more than anyone else in the league
2nd down to 7th consists of the remaining European challengers and Sampdoria, who actually sit 16th! Potentially unlucky to be that far down based on shot counts
Premier League
Premier League 2019/20 – Total Shots Ratios and Total Shots on Target Ratios
Man City and Chelsea lead the way but are both pretty inefficient considering their shot dominance.
Liverpool have clearly been the best team in the league and are 3rd here, with a suggestion they have been one of the more efficient teams. This goes to show that game state can have an impact on shot counts.
Doesn’t look so good for Tottenham/Arsenal who are actually below 0.5 for Total Shots on Target Ratios, either by chance or design they both aren’t getting shots on target as much as top half sides expect let alone Champions League teams.
Ligue 1
Ligue 1 2019/20 – Total Shots Ratios and Total Shots on Target Ratios
Lille are way up there almost with Paris which bodes well for them!
Lyon look to be an efficient mid table team, which goes with their below par season so far. Expected them up with Marseille/Lille at least.
Bundesliga
Bundesliga 2019/20 – Total Shots Ratios and Total Shots on Target Ratios
Top 4 looks as expected, with Gladbach’s incredibly efficient shot to shots on target helping them keep pace.
The bottom half seems to be pretty inefficient, Hertha don’t appear to like shooting on target that much..
Considering the suspensions of all major leagues, I thought it would be a good chance to catch up on how each one. Specifically here I’m taking a look at the distribution of minutes played by players in each team by the age of those players. The inspiration for this came from Real Sociedad and seeing that the core of their team has been a bunch of early twenty year olds and they currently sit in 4th should the leagues end now. This did seem unusual, but to compare with other teams this sparked a project that I have come across much more time to complete.
The data for this analysis has come from transfermarkt.com. Using the helpful tutorials on FC Python, specifically https://fcpython.com/scraping/introduction-scraping-data-transfermarkt, means all of the data you see is possible to get into a much cleaner, easier to use table or dataframe.
Minutes played is in all competitions during the 2019/2020 season up to the latest round of games before league suspensions.
I’ve taken a look at the top 5 European leagues and noted down some interesting, some weird and some funny things that came up.
La Liga
Age x Minutes Played in La Liga so far in 2019/2020 season
Real Sociedad
The initial inspiration for this project, so it’s nice to confirm the intuition that allocating lots of minutes to a younger group of players isn’t the norm. They have done well this year, I expect this team to have players poached sooner rather than later.
Real Madrid
What struck me with this was the gap between the core 7/8 players in their prime ages and the rest of the squad. They are always in ‘win now’ mode so it’s hard to ease in any youngsters, especially with the expectations of the last decade. But they’re going to need to start to trust a few more of the younger players they actually have an abundance of.
Atletico Madrid
In my head, Atletico’s team is full of 30+ year olds. They are all just passed their prime and have all the experience and tactical nouse a single team could contain. Then I see that the majority of their team is late 20s, actually just hitting their prime. They’ve got some kind of weird, Simeone style conveyor belt going on behind the scenes there.
Ligue 1
Age x Minutes Played in Ligue 1 so far in 2019/2020 season
Lyon/Lille
Another case of lots of minutes played by young players, not too surprising that it’s Lyon and Lille. However worth pointing out again because this is still very much out of the ordinary and some teams seem to be able to consistently do this.
Rennes
This outlier up in the top left corner is Eduardo Camavinga, born on November 2002. He’s still 17. He’s on course to play 3000 minutes this year at centre midfield. He’s pretty good.
Montpellier
This other outlier in the top right is Vitorino Hilton, born in September 1977. He’s 42. He’s on course to play 3000 minutes this year at centre back. I had never heard of him before. He’s 42 and playing 3000 minutes in Ligue 1. I have gained much respect for him.
Bundesliga
Age x Minutes Played in Bundesliga so far in 2019/2020 season
Gladback/BVB
Obligatory lots of minutes for young players alert here. No surprise from Dortmund, but Gladbach are just a notch or two below in terms of the quality and quantity of minutes they’re getting from younger players this year.
Liepzig
RB Leipzig should also be in the lots of minutes for young players, but I thought they deserved a separate mention just because they ONLY play young players. There might be a virtual barrier around the training ground which doesn’t let you in after your 30th birthday.
Paderborn
Paderborn are currently bottom of the Bundesliga and look to have generally spread the minutes around, maybe trying different players or tactics to find something that works. I haven’t watched them. But interesting that the player with most minutes played is 22 year old Sebastian Vasiliadis in centre midfield. Is he the player the coaches trust the most? Or have they had injury troubles to other key players? He could be staying in the Bundesliga next year.
Serie A
Age x Minutes Played in Serie A so far in 2019/2020 season
Juventus
If there was ever a ‘win now’ team’s age profile, it would be this one. High proportion of minutes given to age 30+ players means that surely a rebuild is coming soon. De Ligt/Demiral are probably the start of that. (Note Buffon in the bottom right skewing the x-axis for every other team.)
AC Milan
The only really negatively correlated distribution I’ve seen, lots of minutes for young and not so many minutes for old players. I’d heard that Milan had made a decision to go in a different direction than overpaying just-past-their-prime players on long contracts, seems like they’re at least giving younger guys a go.
Atalanta
Special mention here goes to the island of players in their prime that Atalanta seem to have collected together. Hopefully they have a Gasparini type conveyor belt ready to go.
Premier League
Age x Minutes Played in the Premier League so far in 2019/2020 season
Dwight Mcneil
This is probably my favourite distribution of all. And yet there is nothing actually surprising about what there is to see. Burnley are a team of all old/in their prime players, and then there’s Dwight McNeil. Come on Sean, give him someone from his own generation to talk to at least.
Wolves, Sheffield Utd don’t rotate
There’s definitely something to be said here about team understanding and having consistent line-ups. All these teams have a group of players playing the majority of their minutes, all these teams arguably perform above expectations. This may be confirmation bias as I haven’t checked the cases where core teams underperform. Wolves have played more games than the other teams in Europe, and still don’t rotate. Looking at you Conor Coady at 4000+ minutes already.
Aston Villa
The obligatory team with lots of minutes for young players is Aston Villa? They’re not especially seeing the success that other synonymous teams around Europe are having, probably due to this being mostly debut seasons all at once in a relegation fight.
That about wraps it up, if there are any interesting things you have spotted then give me a shout! Once again, this wouldn’t have been possible without starting off with getting the data from transfermarkt so huge props to FCPython and their website which does a great job. Check them out at @FC_Python.
Chances Created is a metric which tries to quantify the number of goal scoring opportunities that a player is directly involved in. Opta definition is Assists + Key Passes, where Assists are passes (final touch) which result in a goal from the subsequent play and KP are passes which result in a shot that doesn’t become a goal. So chances created can be reduced to the final passes (touches) before another player has an attempt at goal (and scores or doesn’t). As I’ve discussed on podcast The Monthly Football Podcast, Assists alone are pretty random since you rely on the shot actually going in the goal, so chances created is a bit less noisy and should more reliably predict future assists than assists actually do due to the sheer volume of chances created and opportunities for goals to be scored rather than relying on goals actually being scored which is hard.
Chances created relies on a player to actually have a shot at the end, otherwise there is no record of the opportunity. Opta also have ‘Chance Missed’, which is defined as a big chance opportunity where the player doesn’t get a shot away. Chance missed will be attributed to the player who has the big chance and decides not to shoot, which doesn’t help the creator who provided the chance. If we assume that the miss is largely due to the player not executing an attempt, then mapping these chances missed back to the creator in addition to chances created would give credit to creating the opportunity and not punishing them for something out of their control, such as the forward deciding to delay a shot and missing the chance to.
Chances Denied Metric
As usual, chances created and most quantified statistics deal with the offensive side of the game since it’s more tangible. Shots are there and they happen, counting them is pretty straightforward. A bit less straightforward is to count the passes prior to shots, with chances created. Both of these can be tracked over many events and quantify expected outcomes based off similar situations in the past, this results in expected goals and expected assists. What is not straightforward is how to quantify the benefit of defensive actions.
We can count tackles, blocks, interceptions and recoveries, however, much like steals, blocks and rebounds in the NBA, they don’t quite tell the whole story about how a defence works. Weaker teams are asked to defend more since they have less possession, this means they have more chances to rack up interceptions, tackles and recoveries. Possession adjusting these measures helps somewhat to normalise these differences, which means that we can compare the frequency of each action assuming they all have equal chances to do so. However it’s still hard to differentiate the quality of the actions, or how important they were to each team.
Chances denied are an attempt to quantify how much of an opportunity was denied by an interception or ball recovery. In a purely defensive, denying your opponent a goal scoring opportunity, sense, recovering the ball in the middle of the pitch is not as important as recovering the ball on the edge of your own box. Expected threat, created by Karun Singh (@karun1710), is a metric which quantifies how likely a team is to score from each location on the pitch within the next 5 actions. If we assign the xT to a recovery or interception or tackle considering the location on the pitch it occurs then we may get a proxy for how important each action was. Since defensive teams will get more opportunities, it may be worth possession adjusting this also to compare like for like.
The general concept trying to be captured here is to quantify the quality of chance or potential quality of chance that is denied due to the action taken by the defender. This quantity can be given solely to the defender making the action or collectively assigned to the players involved to appreciate the team aspect of defensive play. There is a question whether to include tactical fouls in here as well as legal ball recoveries, but will save that for another time.
Following on from the previous post where I tried to talk through why space and structure matters in football, this post here will try (emphasis on try) to quantify the concepts. The inspiration for this method of quantifying structure has come from looking at event data and trying to combine that with a notion of structure for each event.
When picturing each event, it’s at a point in time of a match with the known locations of each player. They’re snapshots in time with a load of information about how each team is organised for this specific event. These can be plot individually on a pitch, with a visual representation for each event to provide context. If you do plot each event individually, as you’d expect, each plot will look different as players move around the pitch. This difference is what I would like to quantify. Each event has a bunch of player locations in relation to the pitch and ball locations, is there a way to quantify this specific set of locations for an event? If so, can we see how that quantity changes when moving on to the next event?
If a team is defending and they have a certain quantity attached to their structure during a specific event, when the offending team does something which changes the defensive team’s structure massively and causes a goal scoring chance then I’d expect this quantity to have changed significantly to reflect the change in scenario on the pitch.
In the brief research I’ve done trying to find something that fits this criteria, it seemed sensible to take a look at network graphs. They have nodes which can represent players and edges which can be weighted depending on distances between the players at each event. Networks have been used in football in the past with reference to passing metrics and average positions to quantify and qualify different styles of play. They’re usually aggregated views of whole matches, whereas this idea is to sort of create a time series of individual sequential events each represented by networks using distances to represent how a match unfolds. For each match there would be a network representing each event, this allows a distance metric to be calculated between each event to represent how significant or important an event was in changing the structure or immediate flow of the game. Since networks don’t inherently care for locations, to compensate for this I have added in the locations of the centre of the pitch, each corner and each goal to reflect movement around the pitch.
For example, a pass between centre backs intending to maintain possession and cycle the ball may not have such a large difference in structures before and after the pass of either team. Whereas a through ball which plays a forward through on goal and cuts through the defence will have a much larger difference in structures before and after the through ball. This is the type of distinction I hope that will be quantified.
Enough theory, let’s try and see a simplified extreme example. Since for each event all player locations are necessary and that data is both hard and expensive to come by, I have created an extremely unrealistic event which hopefully shows the concept.
Reminder on how to go about plotting a pitch using the ‘SBpitch’ library.
There are no immediate goal scoring chances for the team in possession. We can calculate a distance matrix based on the distances between each player, the ball and points on the pitch. This distance matrix will help to create a network which looks entirely unappealing but contains all the information we want.
The second event is immediately after the first event above, a pass has been made to the forward who receives the ball in a much more advanced position. Amazingly, there has been no attempt to block or deny him any space, if anything the defence has moved completely out of the way. This is pretty poor defending with a pretty poor defensive structure after the pass.
Again we can create a distance matrix which helps create an unappealing network representation of the each player’s location in relation to each other , the ball and points on the pitch.
We have two events, one before a pass is made with the defence in a seemingly comfortable position and the second after a brilliantly executed pass that caused the defence to immediately abort mission. There is a clear difference in the players locations and scenario that can be seen from the pitch view, hopefully comparing the networks can reflect this intuitive difference.
The package NetworkDistance has several metrics which aim to compute how difference several networks are form each other using their adjacency matrices. The distance matrices that we have calculated are weighted adjacency matrices and should be appropriate candidates. It’s worth noting the obvious, that these are fully connected, undirected and weighted networks so not all measures will be appropriate. I am no expert in quantifying networks, however some research into the measures led to the intuition that the best candidates for representing the differences seen on the pitch won’t involve counting or replacing edges or looking at node specific measures. This is because each network will be fully connected, the only difference is the weighting’s between each node and we are interested in overall differences not specifically individual nodes jut yet, there may be some merit to looking at those.
The types of distance measures that seem to fit these criteria are (weighted) spectral distances, which compare the distance between the Eigenvectors of each distance matrix of the networks or the diffusion distance which is based off heat diffusion and has an element of time involved.
The measures for each is below, though I haven’t got an intuition for the scale I’m expecting these numbers to be as there’s no real situation for comparison. They are split into the pairwise distances between each network and a matrix representing the respective spectra. In this case there are only two networks for two events and so a single pairwise distance.
There are of course some factors that haven’t been considered here such as different areas of the pitch being more important than others. Future ideas would ideally include a weighting that is applied depending on where the ball is located on the pitch. A further improvement to this would be to separate each team for the same event and evaluate their network differences separately alongside the overall difference.
This concept is still a work in progress, but thought it was worth thowing the idea out there. Any questions, suggestions or errors please give me a shout!
I always like the idea that Lionel Messi is such a good player that he creates more space by standing still than other players do running around. Space is a premium on the football pitch as it is, so being able to manufacture more space is a great skill to have. I should clarify, space in important areas of the pitch is a premium. There is actually lots of space on the pitch, it’s just that the majority of it isn’t contested as is considered unimportant. Exactly where these important areas are is up for debate, but generally accepted is that the areas close to each goal are more important than others. Being able to manufacture space in these important areas of the pitch is a great skill to have, and one that ultimately determines how well a player and team will perform.
This is the first part of what will likely be a few entries on my thoughts about Space and Structure’s importance in football.
Football is a simple game; the opposition players make it complicated. Putting the small round thing in the large rectangular white thing is a pretty simple concept, and is easy to do when there are no other players trying to stop you. For example, it’s much easier to score an open goal than it is to score in the resulting play from your own goal kick. Aside from the distance, the main obstruction is other players actively preventing your progress up the field towards their goal.
Denying the opposition comfortable possession in important areas of the pitch is a desirable feature of a well working defensive system, whilst gaining comfortable possession in important areas of the pitch is desirable when attacking. Whole styles of play are designed and implemented with both of these dimensions in mind.
Guardiola’s Barcelona used quick, short passing to probe and pull a defence out of shape before exploiting the available space to create high probability goal scoring chances.
Simeone’s Atlético Madrid employ a disciplined low block where defenders deny space and cover each other, whilst not over extending.
These are two opposite extremes of the same coin, both systems have an established structure which maintain control over the space in important areas of the pitch.
Guardiola’s Barcelona worked so well for many reasons, but partly because they were able to consistently pull defenders out of position and distort the structure that the defending team had employed. Once the structure was out of shape, it became much easier to manufacture space where they wanted and create goal scoring opportunities.
Simeone’s Atlético Madrid consistently denied goal scoring opportunities partly due to their individual and structural discipline. They maintain their structure and ensure contingency plans are available, such as double teams and covering defenders, and effective when required.
It’s clear that managing and controlling space in important areas of the pitch is crucial both with and without the ball. The best attacking teams seem to make defensive efforts obsolete, whilst the best attacking teams make defending look so simple. Quantifying contributions to attacking play is a more well established due to individual measurements such as shots, goals, assists and now also ‘Expected’ metrics. This is since scoring goals has been considered an individual achievement and readily quantified by how many goals a player scores themselves. Defensive contributions are harder to quantify and much more nuanced. There are individual metrics such as blocks, tackles and interceptions, however these don’t always correlate with reduced goals conceded. Weaker teams are put in positions to perform these actions more often than stronger teams, but they also concede more goals.
As individual contributions are less important defensively, it seems more reasonable to seek to quantify defensive efforts using team-oriented measurements. In different phases of the game, teams will adopt a shape to their team which reflects both what they want to protect and how they want to protect it. For example, a team may retreat and allow the opposition to carry the ball out of their half but as soon as they enter their own half, they will immediately apply pressure. This suggests that they see the important areas of the pitch in their own half and want to protect this area. Whilst a team may adopt a high press and immediately press the opposition in their half, with the aim of winning the ball back and countering nearer to the opposition’s goal. This approach suggests that their important areas of the pitch cover a much larger area of the field, with a lower emphasis on their own half. These examples are specific to a point in time and will evolve as the ball moves around the pitch, constant re-evaluation of important areas and reactions between teams are the decisions that individual players must make throughout a match.
Without the ball, a team will want to ensure that their intended structure is maintained. With the ball, a team will try to break the defensive team’s structure. The assumption here is that it’s much harder to create goal scoring opportunities when attacking a defence’s intended structure than once you’ve forced them out of their comfort zone. Great attacking teams can force defences out of their structure more easily, usually by precise ball movement or individual skill moving the ball past opponents. Great defensive teams avoid being disrupted from their structure, usually by being comfortable in a wide array of structures and so effectively always in an adequate defensive shape or forcing the attacking team to play by their rules.
It seems obvious that the team which controls the space on the pitch will control the game. When watching football matches, we can get an intuition about how each team sets up and how that affects the flow of a game, however it’s hard to quantify that intuition. It’s hard to determine exactly what make Barcelona and Atletico Madrid’s use of structure and space so good as they appear to have completely opposite styles. In the proceeding parts to my thoughts on structure and space, I’ll take a look at potential ways to quantify or measure their use of space and structure.
** Re-uploaded with correct y-axis (duh, Messi played on the right..)
Introduction
Over the last few moths, Statsbomb have released all of the event data for matches including Lionel Messi’s La Liga matches. Data this detailed and clean is incredibly hard (expensive) to come by, so to give free access to everyone is amazing and much appreciated!
I’ve only just had a chance to take a look at the data, and seen many great pieces put out already. Considering who the data is of, I don’t think it will ever go out of fashion so it’s never too late to start playing around.
** You do need to have the latest version of R and the StatsbombR package installed
There are almost too many things to look at in this data set, so I’ve decided to try to focus on a specific part of Messi’s game and see what I find.
Messi gets the ball, a lot. And he obviously does great things with it once he’s got it, but taking a look at where/how he manages to get the ball would be interesting. Surely the one thing an opposing team would try to do against him would be to try to stop him getting the ball or at least limit him receiving the ball in dangerous areas. That’s the inspiration for taking a look at where he receives the ball on the pitch.
Data Prep
Load all the necessary libraries. The usual suspects for R data manipulation like plyr/tidyverse/magrittr, plotting graphs and pitches with FC_RStats’ SBpitch/ggplot2/cowplot and access to the data in StatsBombR.
We are only looking at La Liga matches, so let’s only load matches from that competition. There is even a cleaning function ‘allclean’ which adds in some extra columns which will be of use such as x/y locations. We have joined on the season names also as they’re much more intuitive than the season id that has been assigned.
There are events from matches from Messi’s debut season 2004/05 through to 2015/16, consisting of events such as shots, passes and even nutmegs. We’re interested in passes received by the man himself. Note there is also an indicator “ball_receipt.outcome.name” that identifies when a pass is missed, we want to exclude these and only look at passes to Messi that he received (NA values).
Plotting a pitch
To get some perspective relative to an actual football pitch and use StatsBomb’s event location data, FC_RStats has created a function “create_Pitch” which does exactly that. Using ggplot2 and a set of pitch type parameters, it’s easy to plot a pitch with the same proportions as the event data collected by StatsBomb.
This pitch can be used as the base to visualise all events by plotting the x/y locations.
Initial data and visual processing is done, we can now start to take a look at the interesting stuff!
At a high level, we can have a look at all of the times Messi received the ball and plot them on a pitch. This will probably get overcrowded but can start to provide some understanding.
Since eachtime Messi receives the ball is in a specific location, we’ve used points to represent this on the pitch. This looks okay initially, but it’s pretty hard to work out exactly what’s going on and doesn’t really tell us anything we didn’t already know. Messi gets the ball a lot in the opposition’s half.
There are lots of overlapping points, let’s try to get a view of the density distribution to see where specifically he has received the ball the most.
This mostly suggests the same thing, Messi likes to receive the ball in the opposition half. Though we can now also see that there are two “peaks”, one far out wide near the top and one closer to the centre. More central areas are more dangerous, whereas you might get more space out wide to be able to receive the ball easier.
Luckily (definitely not luckily) StatsBomb just so happen to have a flag which identifies events that occurred under pressure. I believe under pressure is taken as having an opposition player within X metres of you actively affecting your decision making.
Let’s take a look at Messi’s ball receives whilst under pressure and under no pressure. I would expect that you would be under pressure more often the closer you get to the opposition’s goal.
I’m not really sure what I expected. It’s pretty hard to distinguish between the two as there are so many points. To further filter the data we can take a look at this in each season.
Now there’s a lot less going on. Remember those two peaks of ball receipts from above? We can see here that this is due to Messi receiving the ball in different areas of the pitch in different seasons. Again, this is something we already probably knew. Messi started his career as a wide forward so will receive the ball out wide most of the time. From 2009/10 onwards he starts to receive the ball much more centrally, coinciding with his time playing as a “False 9” up front. Coincidentally, his already ridiculous production output skyrocketted. Messi getting the ball in central areas = goal machine.
This still hasn’t really answered the question of where Messi recieves the ball under pressure as it’s hard to tell if there’s a pattern to the blue/red or if it’s all just random.
Something that can help here are marginal density plots. These can be plotted along each axis separately and can hopefully display the distribution of ball receipts more intuitively.
Again there’s a bit too much going on on the pitch here, but looking at the marginal distributions across each axis is interesting.
Across the top it looks like there’s not too much difference in distribution between “Pressure”“ and “No Pressure”. There is a higher peak for “No Pressure”“ about halfway inside the opposition’s half which could be due to Barcelona practically camping themselves outside the opposition box and all defenders are on the edge of their own box for the majority of most games.
Along the right is as expected, there are many more pass receives under no pressure out wide.
For the first 6 seasons of his career (2004/05 – 2009/10), Messi actually received the ball closer to goal under no pressure than he did under pressure (distribution across the top), which is pretty incredible and opposed to both what you would expect and what we saw overall. These are the wide forward Messi seasons, which shows just how good he was and how good he was getting at being a wide forward. Where he most often received the ball under no pressure (peak of the top distribution) actually moves closer to the opposition goal until 2008/09.
Then in 2009/10 something magical happens. Somehow he manages to receive the ball under no pressure both closer to the goal (across the top) AND dead in the centre of the field (along the right). Which of course is a recipe for success.
From then on, looks like teams at least tried to put pressure on him when he received the ball close to the goal. Not really sure that worked so much though.
There are a lot more amazing things from Messi’s career hidden away in this amazing data set. Thanks again to StatsBomb for the free access to explore and show off some things that are possible with the data.